

“Apples-to-Apples” Call Stack Comparison Wins Distinguished Paper at PLDI 2020
Like many fields of expertise, programming language implementation often relies on conventional wisdom. But occasionally, when you trace that assumed knowledge back to its source, it is not actually based on scientific evidence. Such is the case with the implementation of continuations, a mechanism that is fundamental to implementing language features such as concurrency and parallelism, and which can be used to get the most mileage out of the multicore processors now standard on most modern computers.
In “From Folklore to Fact: Comparing Implementations of Stacks and Continuations” UChicago CS PhD student Kavon Farvardin and Professor John Reppy sought to bust the myths and empirically judge six different implementation approaches on the same system. The results provide trustworthy guidance for building future programming language implementations, and their hard work was rewarded with a Distinguished Paper award at the 2020 SIGPLAN Conference on Programming Language Design and Implementation (PLDI). The conference will be held virtually in mid-June.
“The goal of this paper is not only to provide an empirical apples-to-apples, or well-normalized comparison of these different strategies for performance, but also to dive into the deep details of all the trade-offs in choosing one of these strategies or developing your own custom strategy.” Farvardin said. “Our goal wasn't really to say whether one is the best or not; we really intended for this paper to present all the information so that people can make an informed decision.”
The research utilized the Manticore system, developed by Reppy’s group at UChicago in collaboration with Matthew Fluet’s group at the Rochester Institute of Technology. The Manticore system implements an experimental parallel functional programming language, which provided Farvardin and Reppy with a level playing field on which to pit different approaches against each other. A competition of this caliber had never been conducted before, Farvardin said, for one simple reason: it’s difficult.
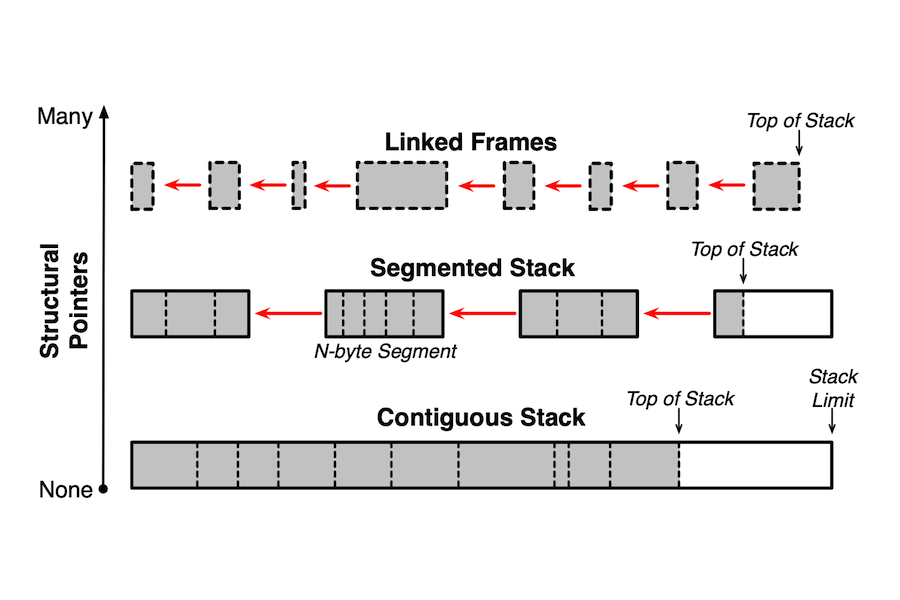
“Nobody really truly understood what the differences were, because nobody in their right mind would ever want to implement so many different types of call stacks in one compiler’s runtime system,” Farvardin said. “It's a huge pain…it's hard enough to get one full-featured call stack implementation.”
But once set up, the authors could compare performance using several dozen different benchmark programs that test aspects such as recursion, looping, concurrency, and other language mechanisms. While small, these benchmarks are good “torture tests,” Farvardin said, for the seemingly routine tasks that can create bottlenecks in larger programs.
Over the range of benchmarks tested, there was no definitive winner. Some approaches (closure-based stacks) offer easier implementation at the cost of sequential performance, others (resizing, segmented, and their own hybrid scheme) offered solid performance across different benchmark types with similar implementation overhead. Only one strategy (linked-frame stacks) was discouraged by the authors, who concluded that the hybrid approach is what they would themselves choose if they were rebuilding Manticore from scratch.
“There's no silver bullet, and we didn't really expect there to be any one strategy that's the winner,” Farvardin said. “It's really up to your language and your priorities. We aimed to be the latest and greatest knowledge on the trade-offs in this space, both empirically and in terms of implementation details.”








