

UChicago CS Receives Several Awards, Presents Virtual Papers at CHI 2020

[Watch video presentations of all 8 UChicago CS papers from CHI 2020]
With computers of various forms now integral to society, the field of human-computer interaction (HCI) has thrived as a multidisciplinary approach to both expand the potential and avoid the dangers of our technology. Each year, the epicenter of HCI is the annual ACM SIGCHI conference, known as CHI for short, which was scheduled for late April 2020 in Hawaii. Though the physical gathering was cancelled due to COVID-19, many CHI authors have presented and shared their work through self-produced videos.
Among those authors are several faculty and students from UChicago CS, who contributed an impressive eight papers to the conference. UChicago research also received multiple commendations, including one Best Paper award and four Honorable Mentions. The innovative research, described below, runs the gamut from a bracelet that jams nearby smart devices and scent-based illusions for virtual reality to systems for detecting undisclosed advertisements on social media and gender stereotypes in text and sound.
The papers also ask provocative questions about model transparency, privacy, and how modern life is affected by ubiquitous technology and algorithmic approaches. In fact, one paper authored by a large cast of of the field’s luminaries (including Pedro Lopes of UChicago CS) proposed that the acronym HCI itself might even be redefined as “human computer integration,” predicting that the future will bring a further blurring of the boundaries between people and their devices.
The UChicago CHI papers will be presented on May 26th as part of a special virtual “CHIcago” session. RSVP information is available here.

One limitation on the realism of current virtual reality technology is the inability to simulate ambient changes in environment such as temperature. So Jas Brooks, Steven Nagel, and Lopes designed an add-on device that uses the properties of different scents to simulate the sensation of warmth and cold. Built from micropumps and an atomizer, the device sprays a chemical (capsaicin for hot and eucalyptol for cold) into the VR user’s nostrils, stimulating the trigeminal nerve and producing a thermal illusion. A demo of the Best Paper Award-winning device shows how users can feel the heat of a furnace, the chill of a winter wind, and even the gas fumes of a generator in a virtual environment.
[Best Paper award]
A less desirable illusion is the “visualization mirage,” a term coined in a paper from UChicago’s Andrew McNutt and Gordon Kindlmann with Michael Correll of Tableau Research. Whether intentional or accidental, data visualizations can distort the meaning of underlying data due to a variety of causes, from dirty data to inappropriate choices in plot design to outright deception. By adapting a technique from software development called “metamorphic testing” to automatically detect and flag these distortions, the authors build the foundation of a “spell-checker” for visualizations that warns users of graphical analytics tools to avoid potential mirages.
[Honorable Mention]
The inverse of an automated system to detect misleading data visualizations is a system that takes data and automatically proposes the most interesting visual representations. Many of the algorithms that currently exist for this task are “black boxes,” offering little control or context about why they chose a particular insight. To remedy this lack of transparency and grant the user more creative control, a second paper from McNutt and Correll, with Anamaria Crisan of Tableau Research, drew inspiration from the centuries-old fortune-telling techniques of Tarot cards. Sortilège, their system for “divining insights” from data, allows users to deal out cards that each contain a question or insight about their dataset, in the hope of guiding a researcher towards the optimal visualization. A demo of their system is available here.
[Part of the concurrent alt.chi conference, which highlights “controversial, risk-taking, and boundary pushing presentations”]
In text analysis, automated systems can measure sentiment, hate speech, and other subjective features. Another target is gender stereotypes, which is particularly relevant today. There are divergent approaches to analyzing text. Today’s common methods on gendered text analysis remain largely unchanged from 40 years ago, and are largely based on a “lexicon” of gendered words created in 1974, when societal views of gender were much different. In contrast, the field of natural language processing (NLP) has been revolutionized in recent years by deep learning models. The area of gender text analysis needed a quantitative analysis to understand the tradeoffs of these divergent approaches, reasoned Jenna Cryan, Shiliang Tang, Xinyi Zhang of the SANDLab group led by Ben Zhao and Heather Zheng and Miriam Metzger from the University of California, Santa Barbara.
Through crowdsourcing, the team created an updated lexicon and tested it in a traditional system against a newer “end-to-end” model that uses deep learning to recognize gender stereotypes in text. The less transparent deep learning approach trained with paragraphs of text instead of individual words, outperformed the lexicon-based approach even with an expanded and updated lexicon, pointing the way to new methods for spotting gender bias in text, from job listings to movie dialogue.
[Honorable Mention]
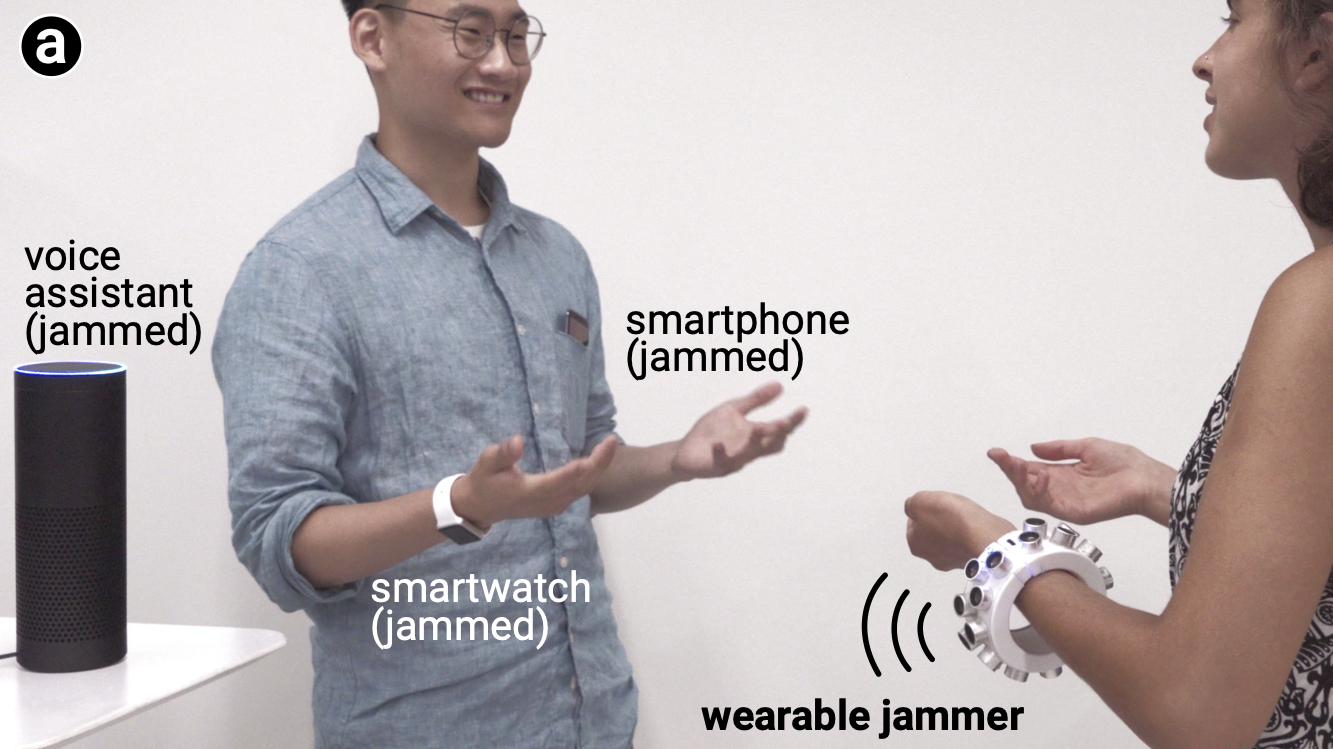
The increased popularity of digital assistants and other internet-connected smart devices has introduced many more microphones into our homes, offices, and public spaces. To protect people’s privacy from these ever-present ears, Yuxin Chen, Huiying Li, and Zhijing Li, students from Zhao and Zheng’s SANDLab, worked with Shan-Yuan Teng, Nagels and Lopes to design a new wearable microphone “jammer” that uses ultrasonic signals to scramble audio recordings. Creatively, the designers used their device’s wearability to solve the common signal-jamming problem of blind spots, as the wearer’s natural movements help increase coverage. The research has already received coverage from the New York Times and dozens of other media outlets.
[Honorable Mention]
Advertisers are increasingly aggressive in collecting and repurposing personal data to target customers online. To assess whether hyper-personalized ads arouse privacy concern and make people less likely to share sensitive data in the future, Julia Hanson, Miranda Wei, Sophie Veys, and Neubauer Family Assistant Professor Blase Ur, in collaboration with Matthew Kugler of Northwestern and UChicago Law Professor Lior Strahilevitz, created a two-part deception study. In the first part, participants answered questions about their romantic relationship, location, and food preferences, the data from which was then used to feed them a customized robotext or banner ad (e.g. “Taylor, treat Ryan to date night at a Thai restaurant this week in Memphis.”) during a second survey one week later. While study participants reacted negatively to these targeted ads as compared to participants who saw a non-targeted ad, they still answered most invasive questions the second survey asked about religion, finances, and pornography habits — raising questions about the degree to which numerous other factors prevent individuals from taking action to protect their privacy online.
[Honorable Mention]
Social media users are required to disclose when they have or will receive payment to promote a product. But some online influencers try to skirt these rules through affiliate programs, where they provide special links or coupon codes to buy a product they are “objectively” reviewing, receiving a cut for each purchase. In their CHI paper, Assistant Professor Marshini Chetty and researchers from Princeton University studied how often content creators disclose these relationships, finding that less than one in ten comply with federal regulations. The team also adapted the detection system they built into AdIntuition, a browser extension that detects these “dark patterns” and warns viewers. AdIntuition is available for Chrome and Firefox.








